

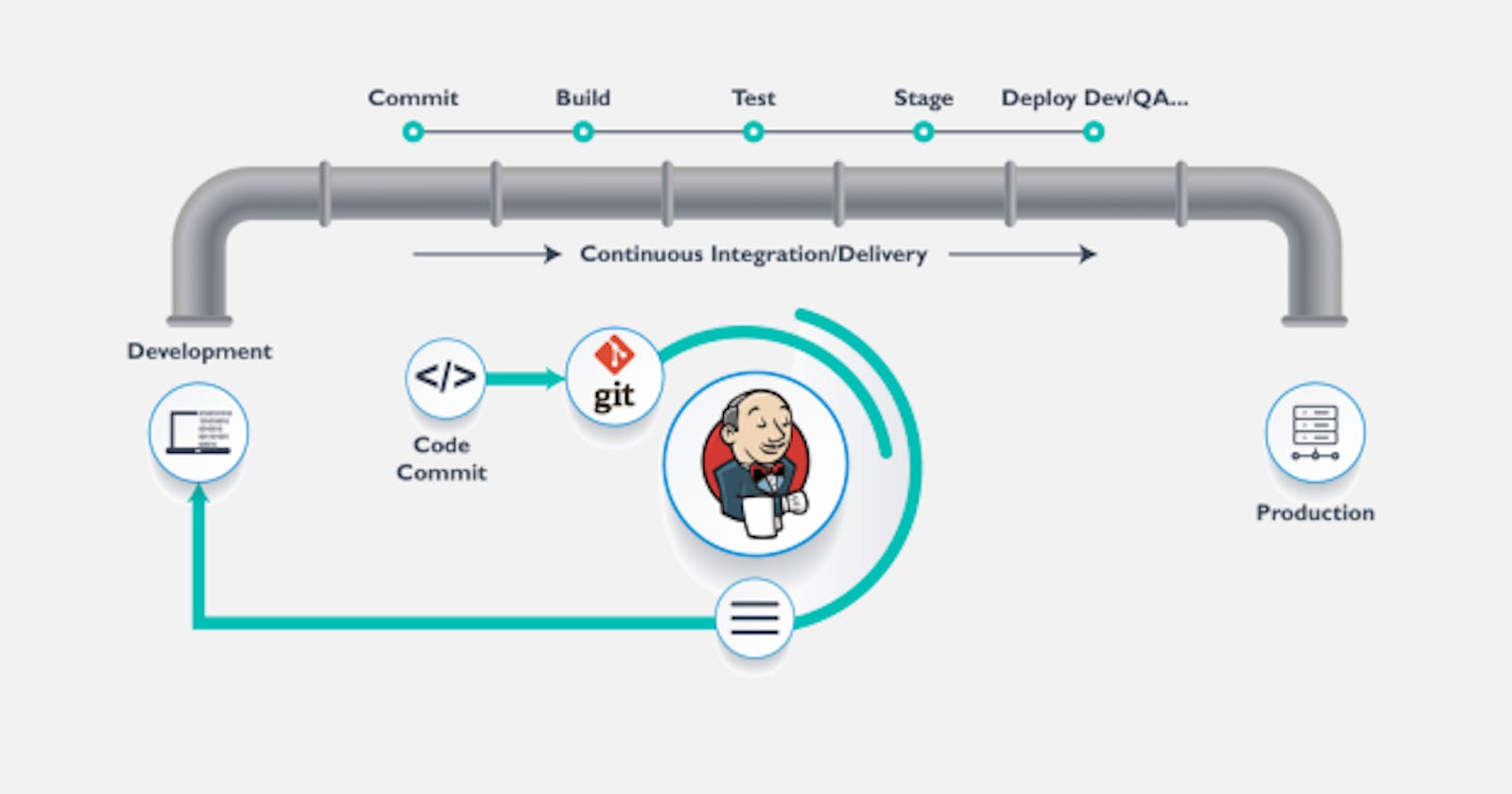
What is a Jenkins pipeline?
A Jenkins pipeline is a set of plug-ins to create automated, recurring workflows that constitute CI/CD pipelines. A Jenkins pipeline includes all the tools you need to orchestrate code committing, building, testing, merging, packaging, shipping, and code deployment.
A pipeline is typically divided into multiple stages and steps, with each step representing a single task and each stage grouping together similar steps. For example, you may have “Build”, “Test”, and “Deploy” stages in your pipeline. Jenkins Pipeline code is written in a Jenkinsfile.
A Jenkinsfile can be written using two types of syntax — Declarative and Scripted.
Declarative Pipeline
Declarative Pipeline is a more recent feature of Jenkins Pipeline which:
provides richer syntactical features over Scripted Pipeline syntax, and
is designed to make writing and reading Pipeline code easier.
They are quite easy to write and understand. The structure may seem to be a bit complex, but overall, it contains only a couple of basic sections. The “pipeline” block is the main block that contains the entire declaration of a pipeline. In this example, we’ll consider only “agent”, “stages”, and “steps” sections:
pipeline – contains the whole pipeline
agent – defines the machine that will handle this pipeline
stages – declares the stages of the pipeline
- steps – small operations inside a particular stage
Let’s check what this structure will look like in our declarative pipeline:
Jenkinsfile (Declarative Pipeline)
pipeline {
agent any
stages {
stage('Build') {
steps {
//
}
}
stage('Test') {
steps {
//
}
}
stage('Deploy') {
steps {
//
}
}
}
}
Scripted Pipeline
Scripted pipelines were the first version of the “pipeline-as-code” principle. They were designed as a DSL build with Groovy and provide an outstanding level of power and flexibility. However, this also requires some basic knowledge of Groovy, which sometimes isn’t desirable.
These kinds of pipelines have fewer restrictions on the structure. Also, they have only two basic blocks: “node” and “stage”. A “node” block specifies the machine that executes a particular pipeline, whereas the “stage” blocks are used to group steps that, when taken together, represent a separate operation. The lack of additional rules and blocks makes these pipelines quite simple to understand:
node {
stage('Hello world') {
sh 'echo Hello World'
}
}
Pipeline concepts
The following concepts are key aspects of Jenkins Pipeline, which tie in closely to Pipeline syntax (see the overview below).
Pipeline
A pipeline block is a key part of Declarative Pipeline syntax. In Declarative Pipeline syntax, the pipeline block defines all the work done throughout your entire Pipeline.
A Pipeline’s code defines your entire build process, which typically includes stages for building an application, testing it and then delivering it.
Node
A node is a machine, which is part of the Jenkins environment and is capable of executing a Pipeline.
Also, a node block is a key part of Scripted Pipeline syntax.
Stage
A stage block defines a conceptually distinct subset of tasks performed through the entire Pipeline (e.g. "Build", "Test" and "Deploy" stages), which is used by many plugins to visualize or present Jenkins Pipeline status/progress.
Step
A single task. Fundamentally, a step tells Jenkins what to do at a particular point in time (or "step" in the process). For example, to execute the shell command make, use the sh step: sh 'make'.
Let's create a pipeline in our Jenkins server and see how it works.
Create New Item

Provide a brief description for your job to help identify its purpose.

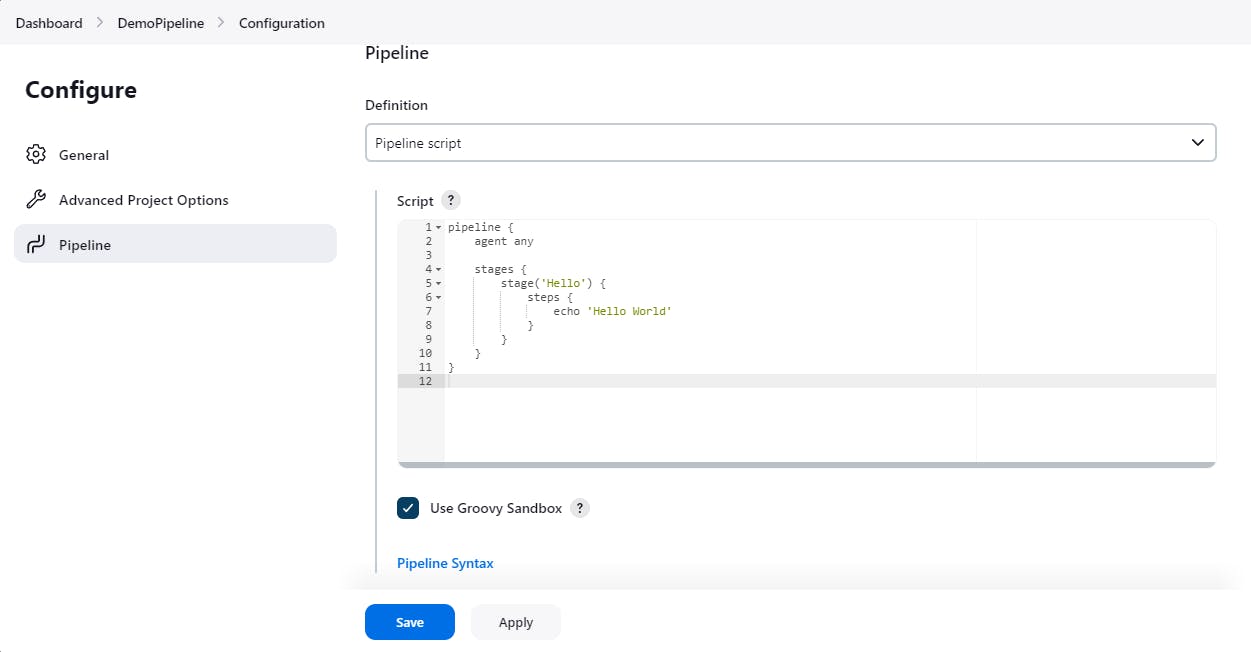
Write a sample Declarative Pipeline to print "Hello World"
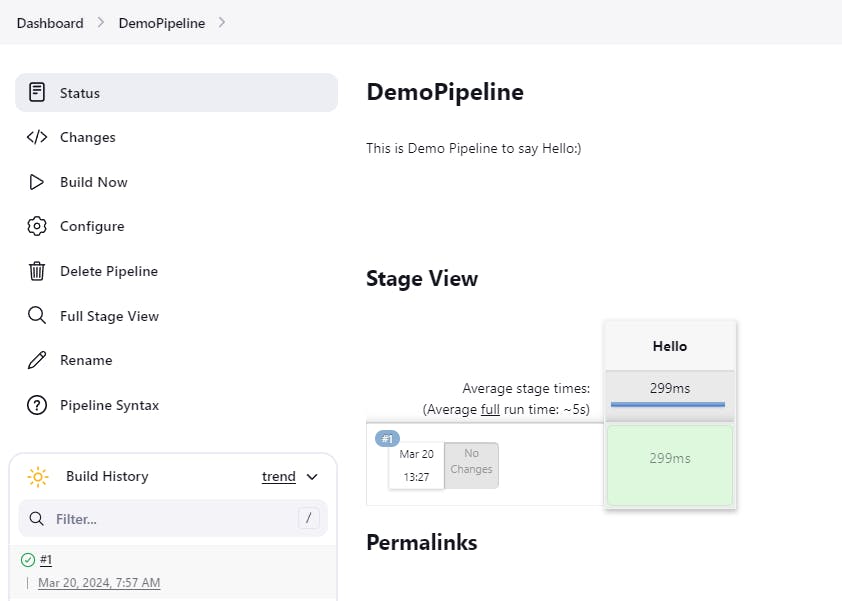
There you go, your first pipeline has executed successfully.
Stay tuned to know more about declarative pipelines and Jenkinsfile, which I will be discussing in my upcoming blogs.